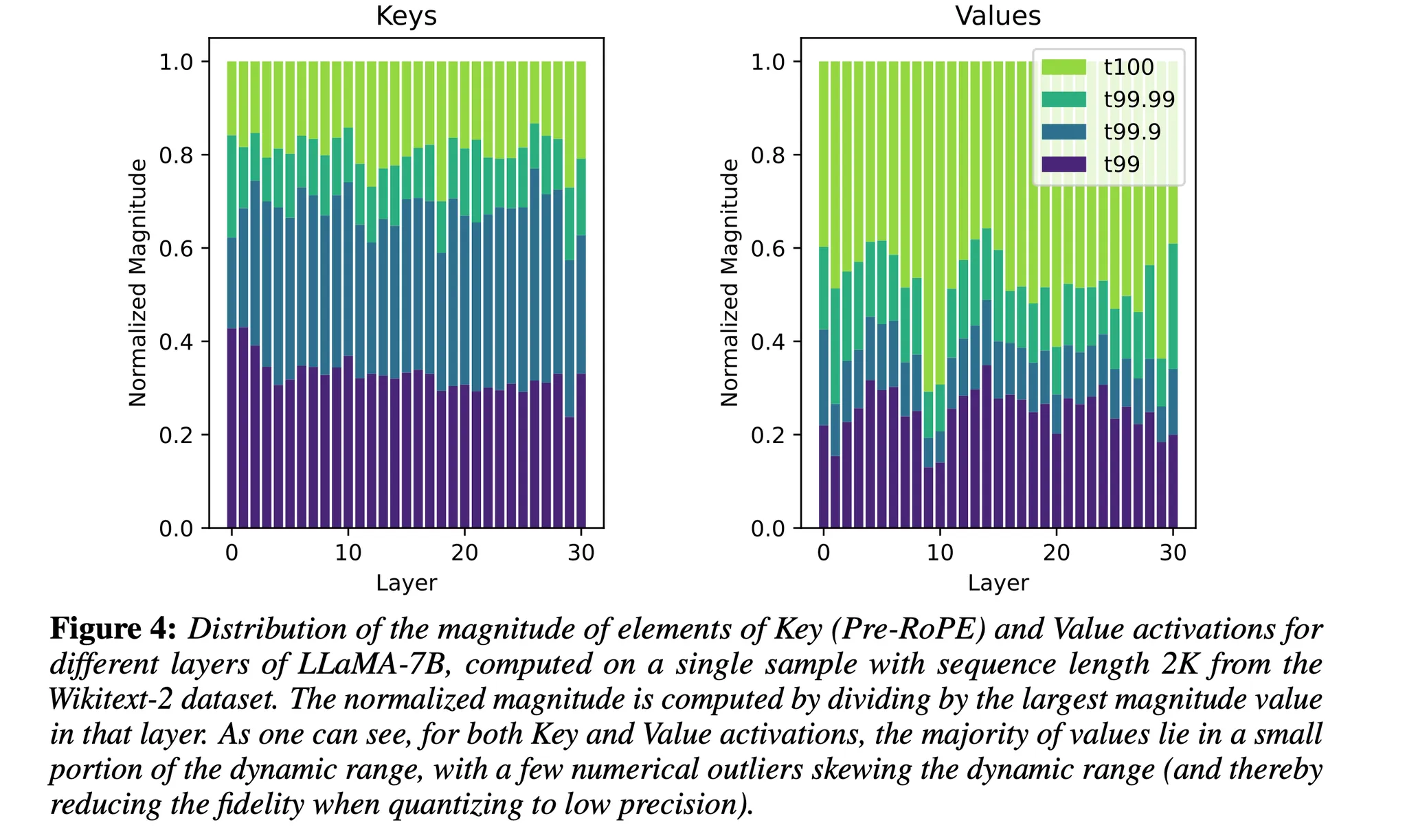
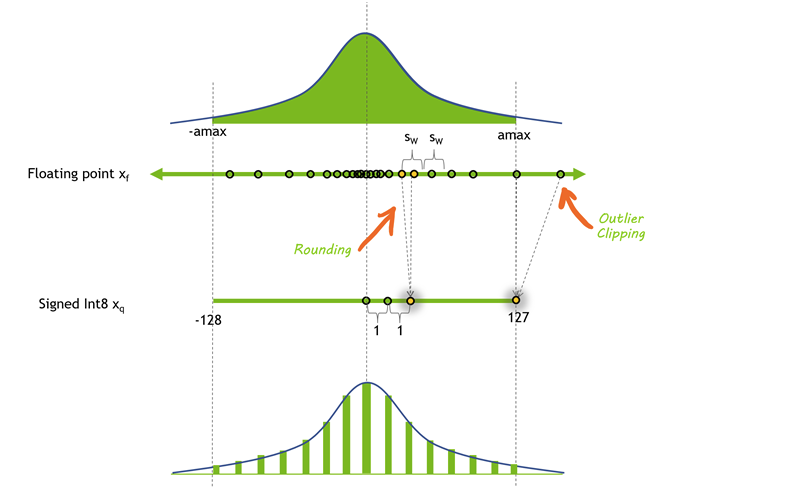
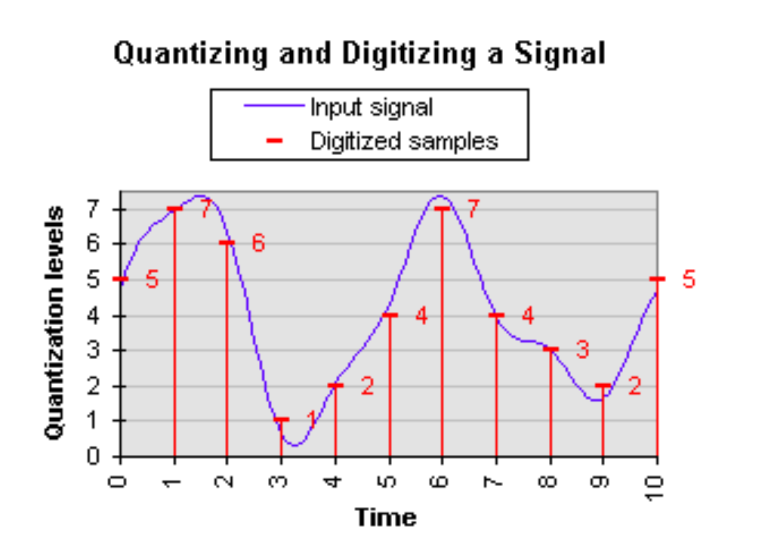
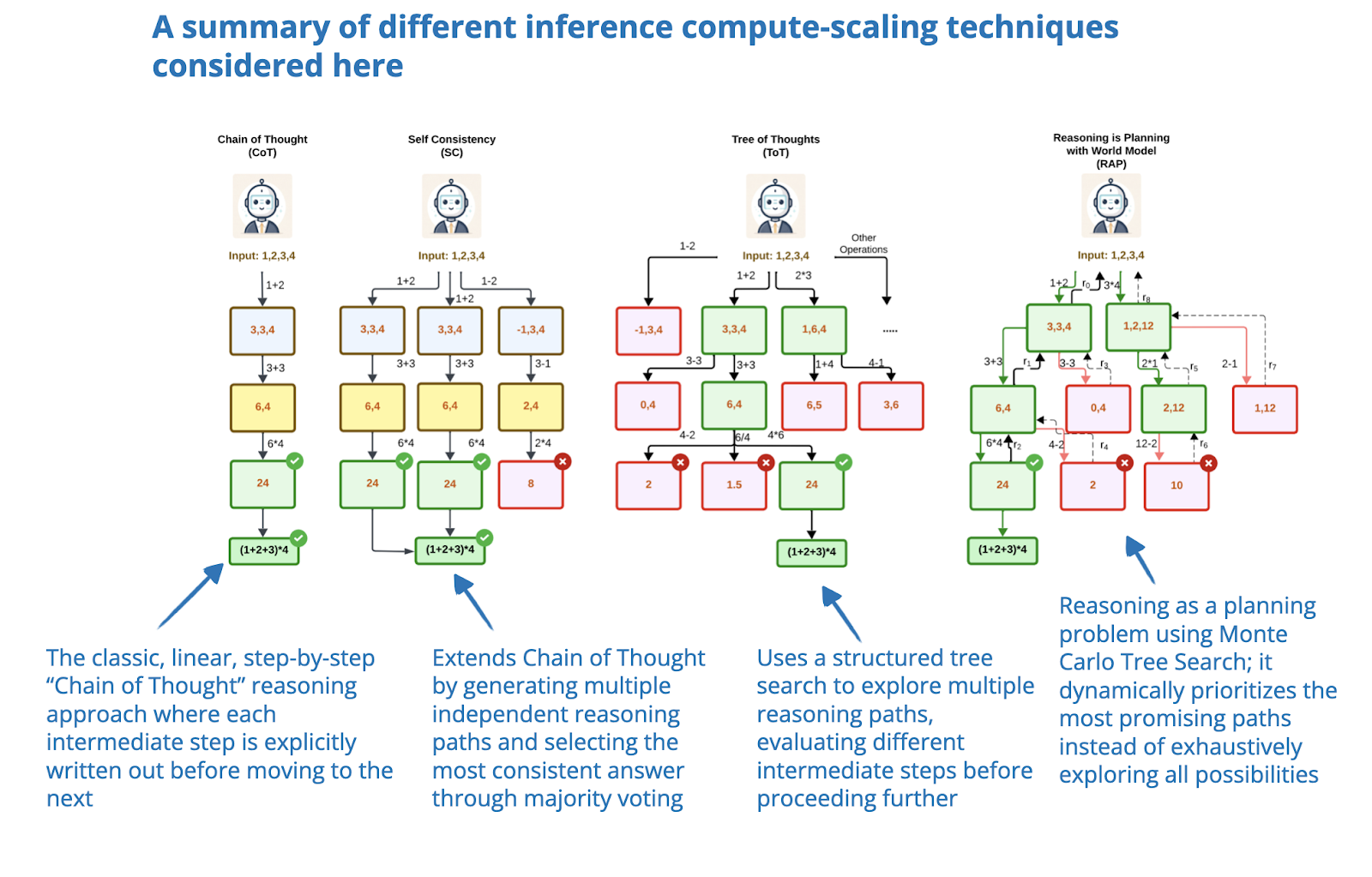
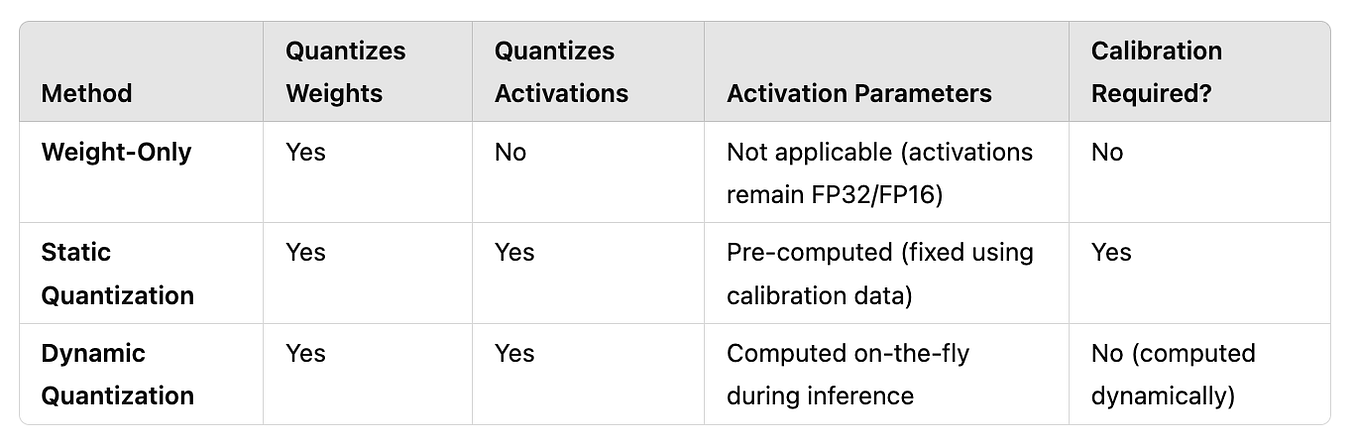
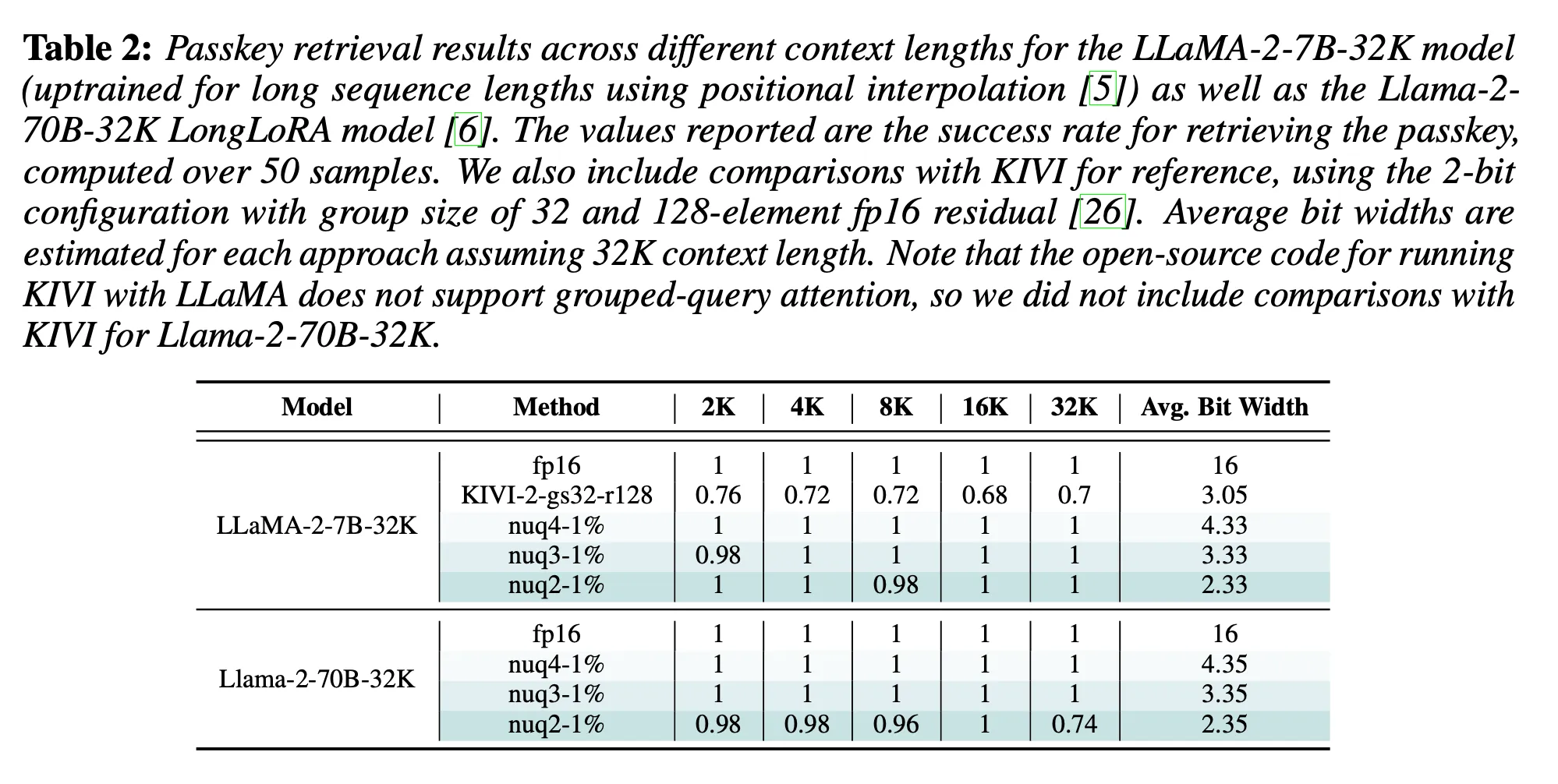
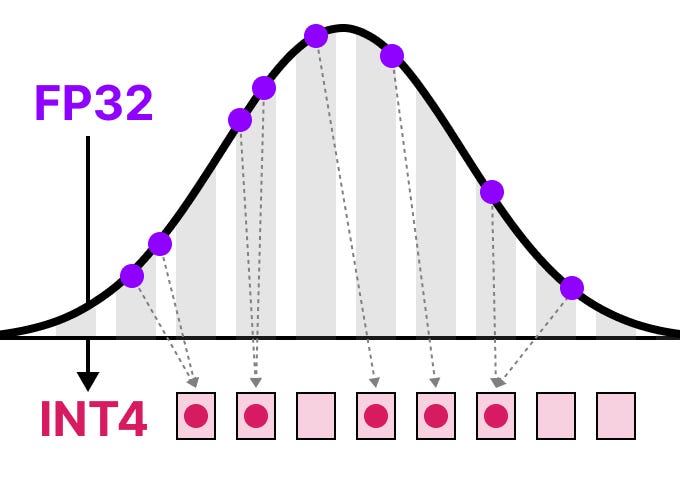
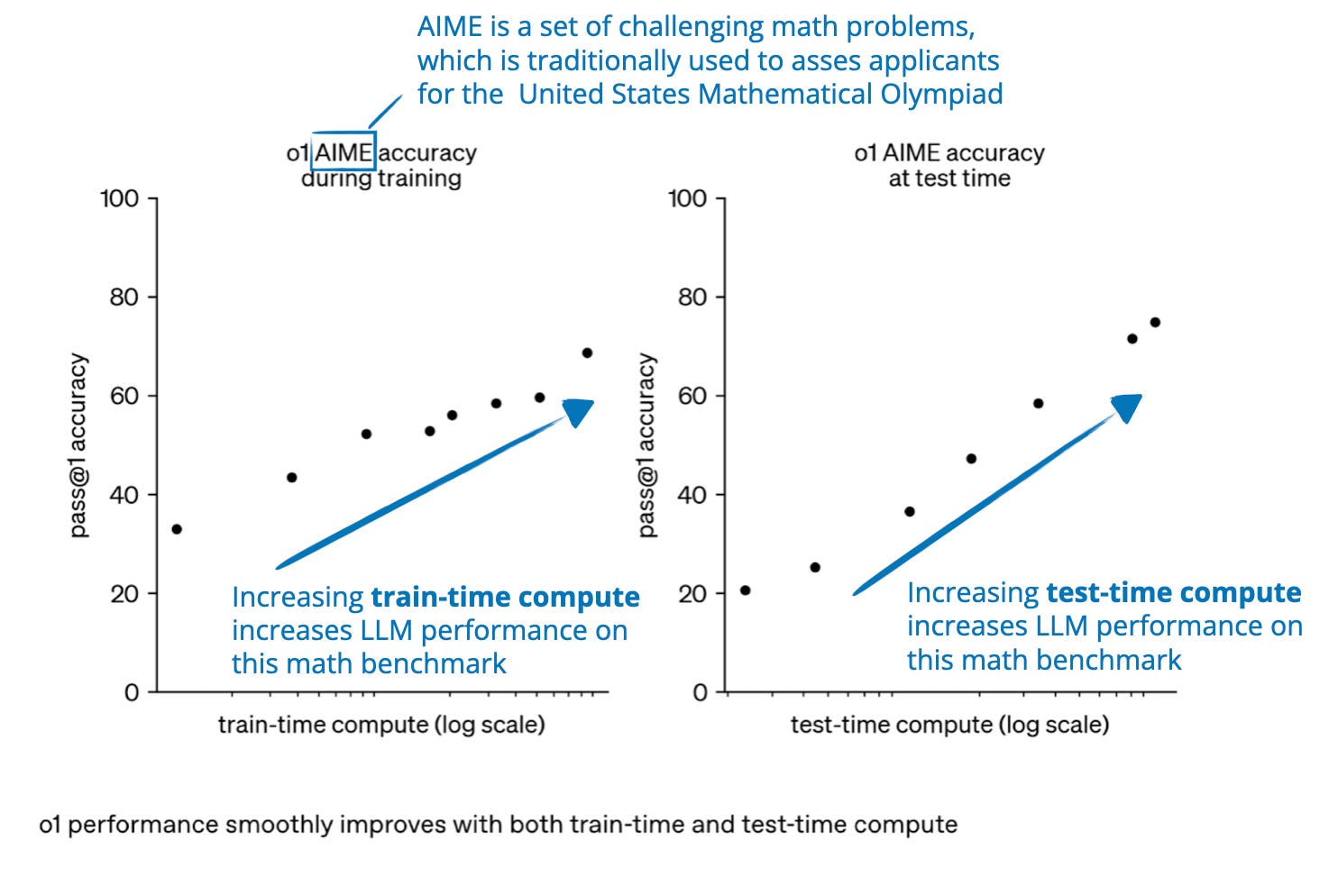
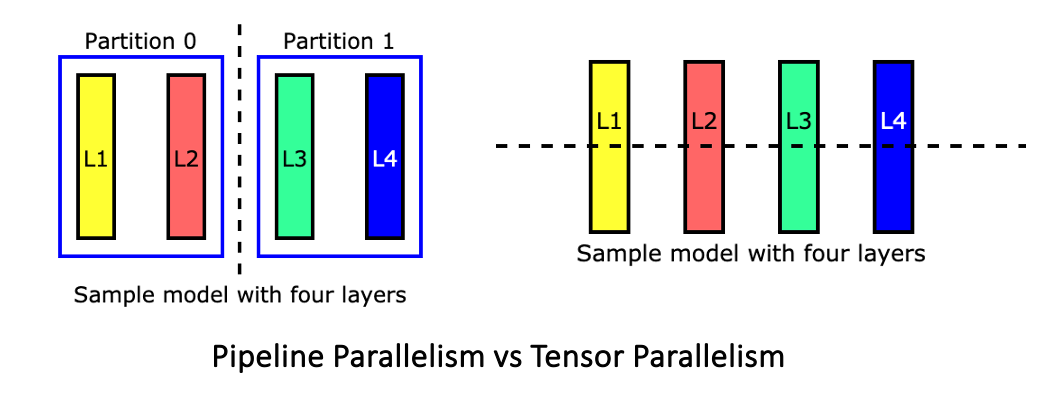
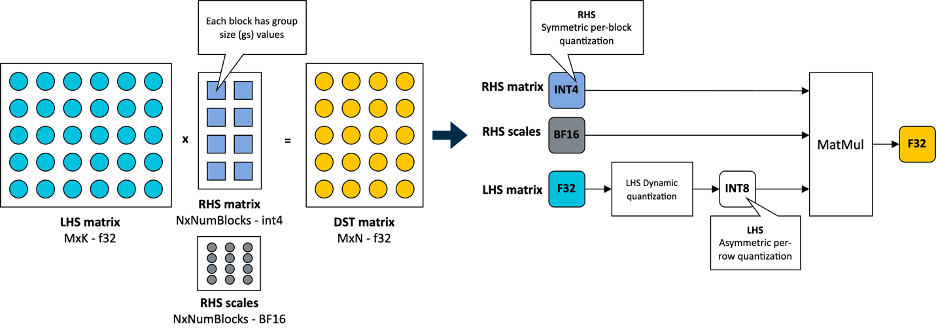
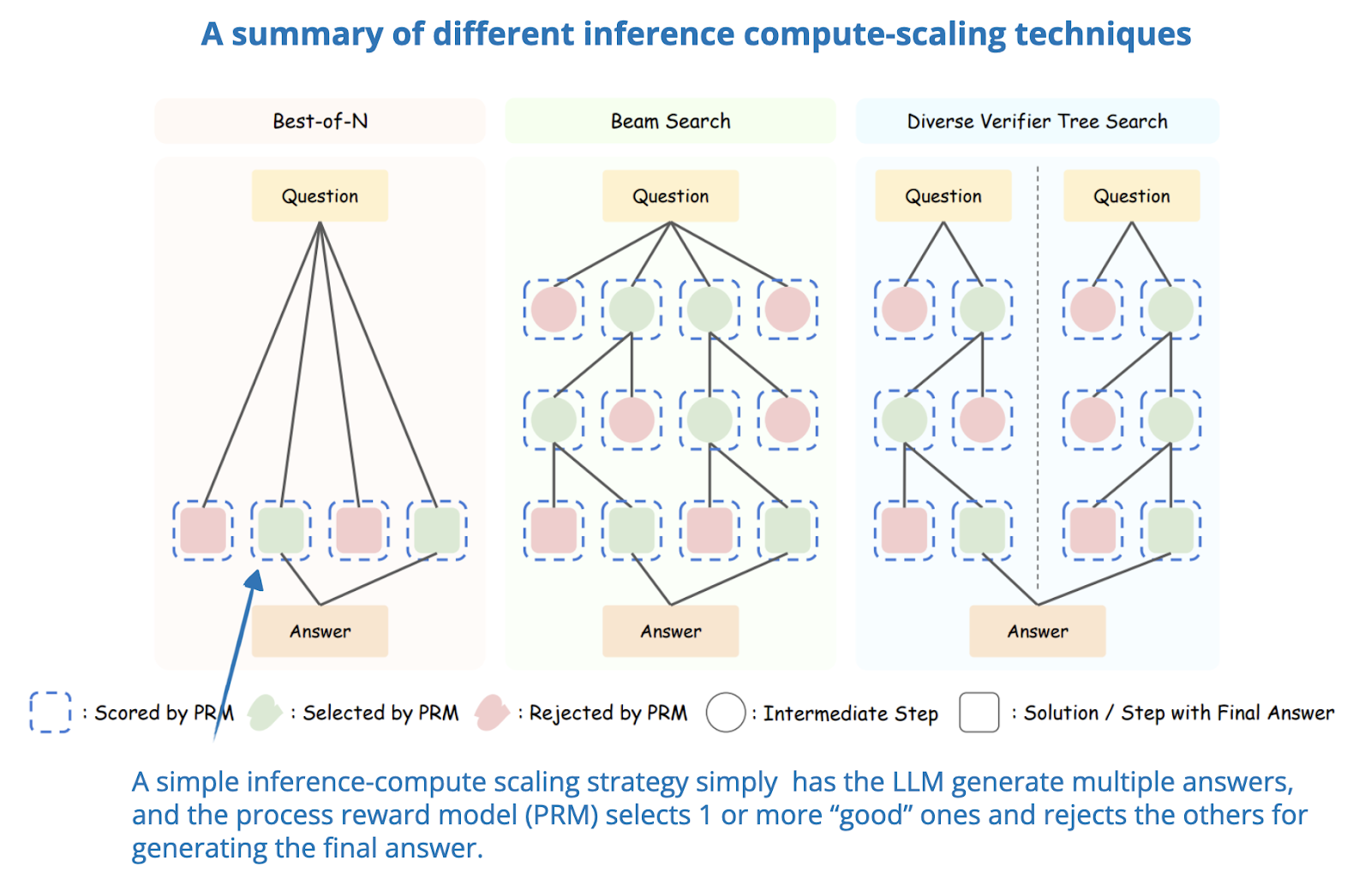
Showing 118 of 118on this page. Filters & sort apply to loaded results; URL updates for sharing.118 of 118 on this page
LLM inference optimization: Model Quantization and Distillation - YouTube
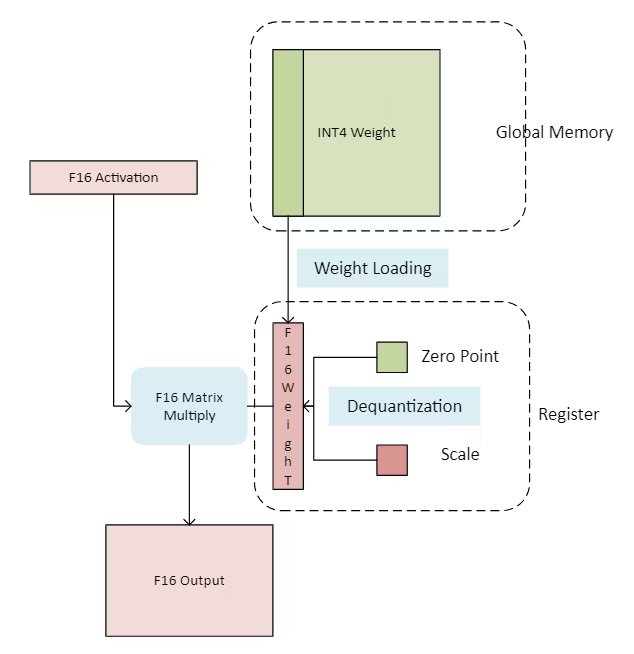
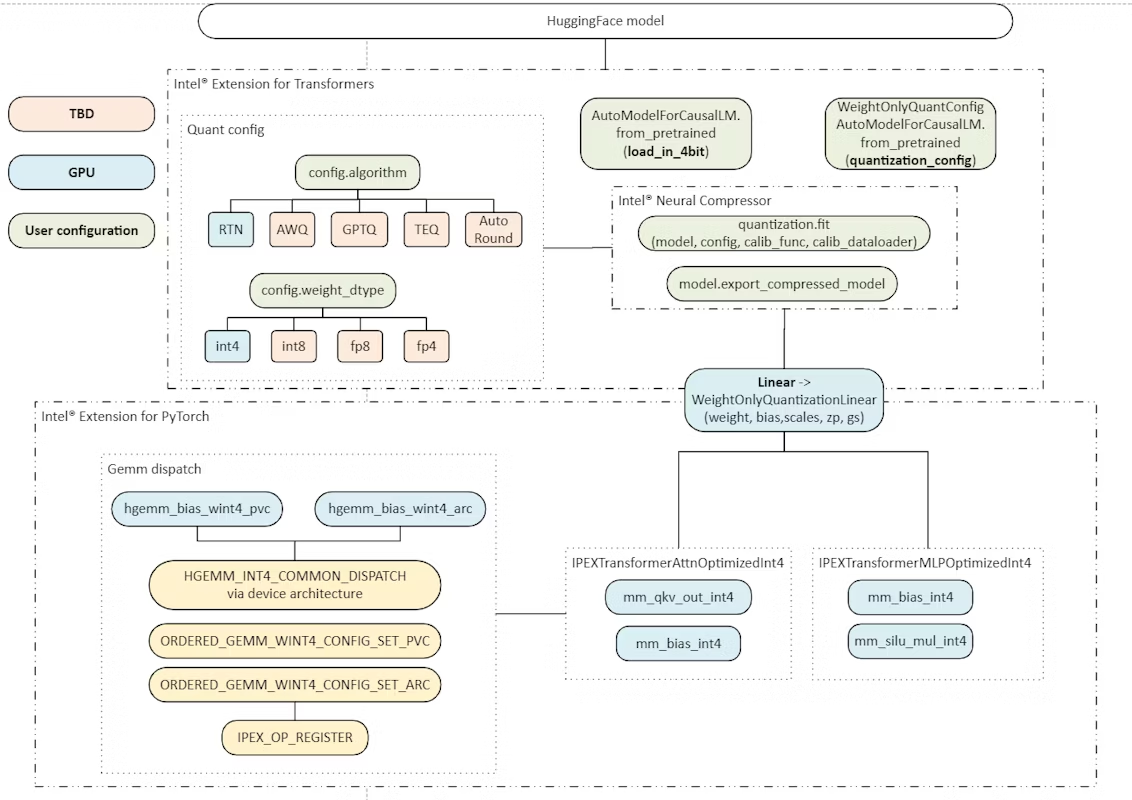
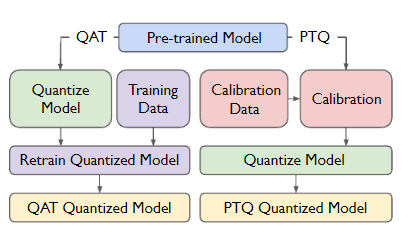
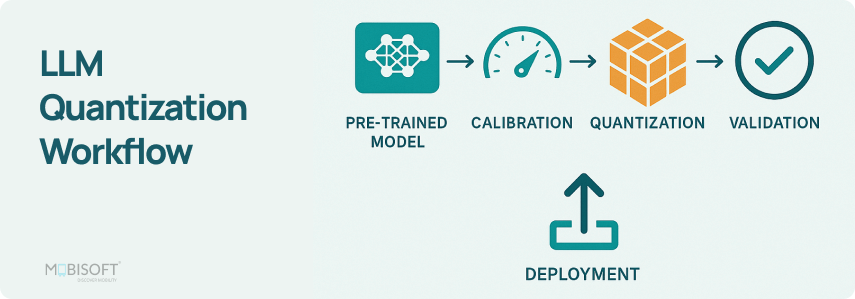
Weight-only Quantization to Improve LLM Inference
8 LLM Quantization Moves for 60% Cheaper Inference | by Hash Block ...
Improving LLM Inference Latency on CPUs with Model Quantization ...
Improving LLM Inference Speeds on CPUs with Model Quantization | by ...
Why Quantization Helps LLM Inference Much More Than LLM Training | by ...
[论文评述] DILEMMA: Joint LLM Quantization and Distributed LLM Inference ...
33% faster LLM inference with FP8 quantization | Baseten Blog
LLM quantization | LLM Inference Handbook
Optimizing LLM Inference with Dynamic Quantization | by Kim, Mingyu ...
Improving LLM inference speeds on CPUs with model quantization | UnfoldAI
Democratizing LLMs: 4-bit Quantization for Optimal LLM Inference | by ...
Democratizing LLMs: 4-bit Quantization for Optimal LLM Inference ...
Optimizing LLM Inference with Speculative Decoding and Quantization ...
Efficient LLM Inference Achieves Speedup With 4-bit Quantization And ...
MoQAE: Mixed-Precision Quantization for Long-Context LLM Inference via ...
33% faster LLM inference with FP8 quantization
The Ultimate Handbook for LLM Quantization | Towards Data Science
LLM Series - Quantization Overview | by Abonia Sojasingarayar | Medium
LLM Inference Optimisation — Continuous Batching | by YoHoSo | Medium
Quantized 8-bit LLM training and inference using bitsandbytes on AMD ...
Top LLM Quantization Methods and Their Impact on Model Quality
Benchmarking Quantized LLM Inference Speed
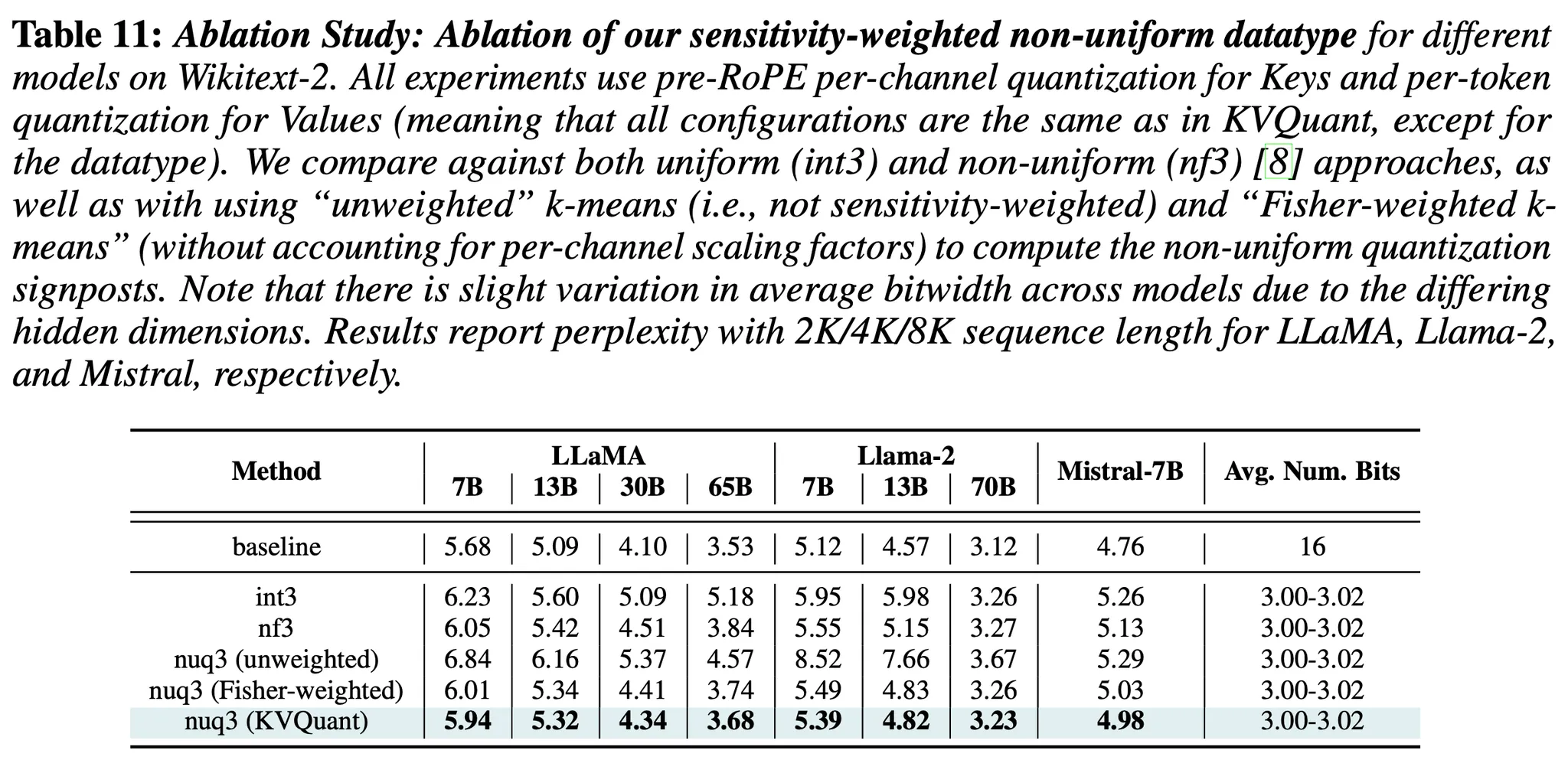
Paper review[KV Quant: Towards 10 Million Context Length LLM Inference ...
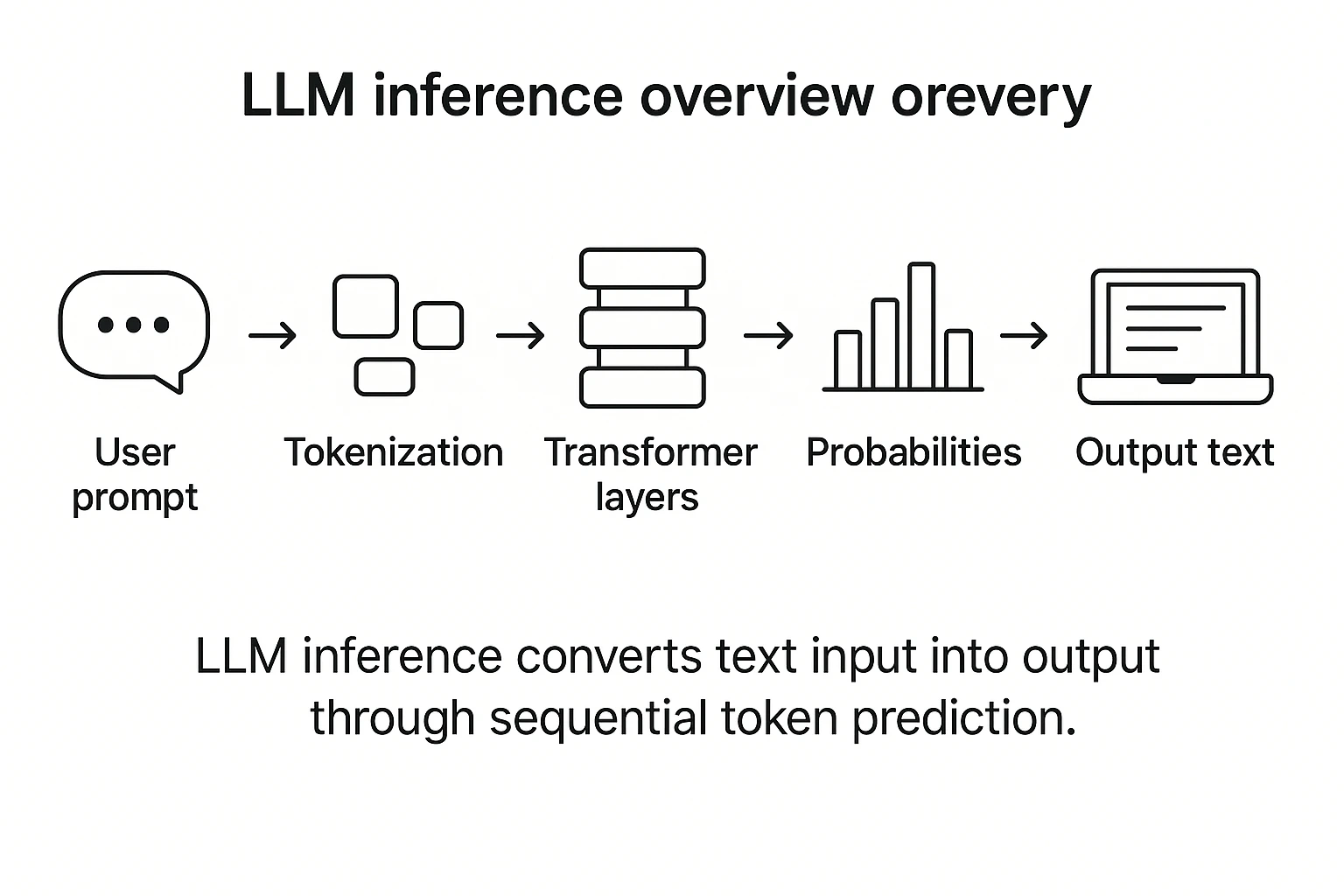
Mastering LLM Techniques: Inference Optimization – GIXtools
Faster LLMs with Quantization - How to get faster inference times with ...
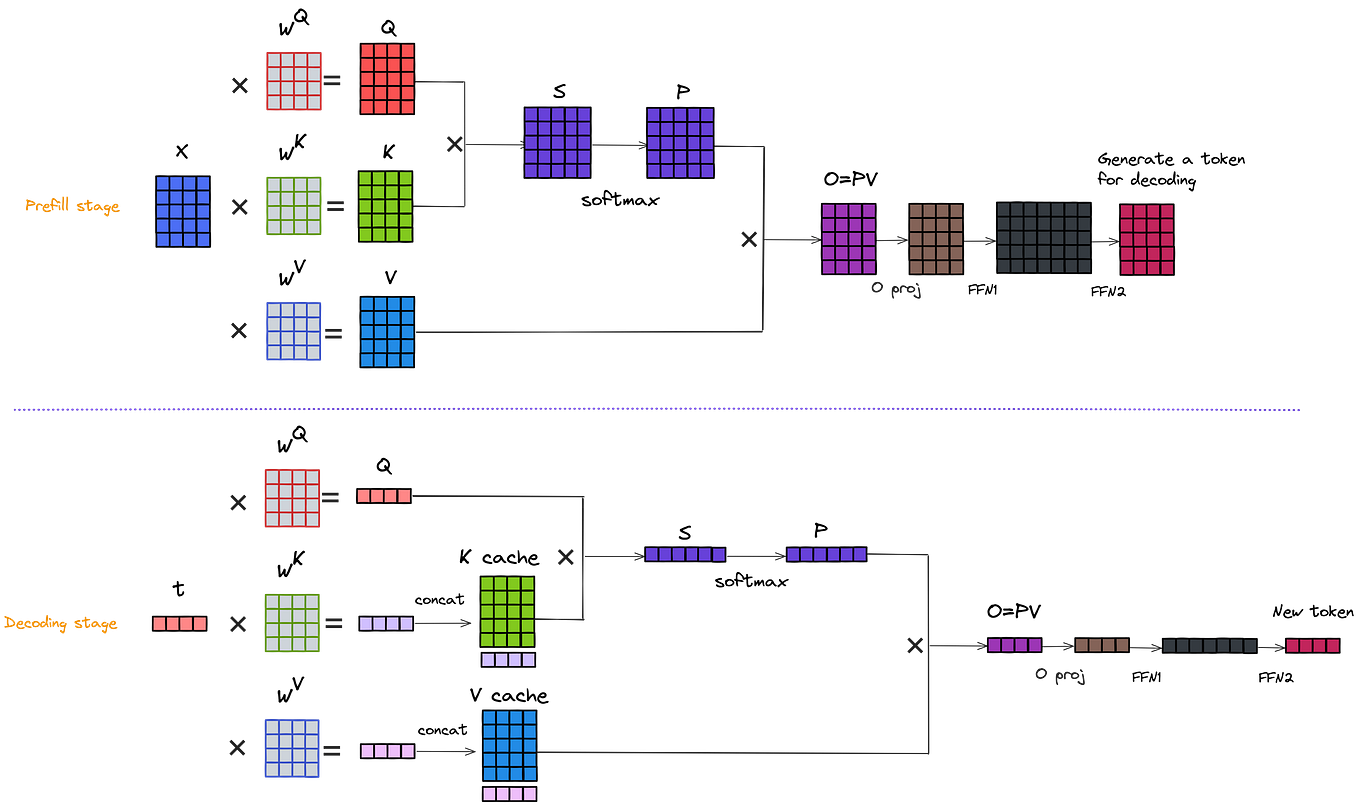
LLM Inference - Hw-Sw Optimizations
MILLION: Mastering Long-Context LLM Inference Via Outlier-Immunized KV ...
(PDF) Sustainable LLM Inference for Edge AI: Evaluating Quantized LLMs ...
An Introduction to LLM Quantization - TextMine
Optimizing LLM Model using Quantization
Power-of-Two Quantization Improves LLM Accuracy And Accelerates ...
LLM Inference Series: 5. Dissecting model performance | by Pierre ...
The Complete Guide to LLM Quantization | LocalLLM.in
A Comprehensive Guide on LLM Quantization and Use Cases
The State of LLM Reasoning Model Inference
How to benchmark and optimize LLM inference performance (for data ...
Demystifying LLM Quantization Suffixes: What Q4_K_M, Q8_0, and Q6_K ...
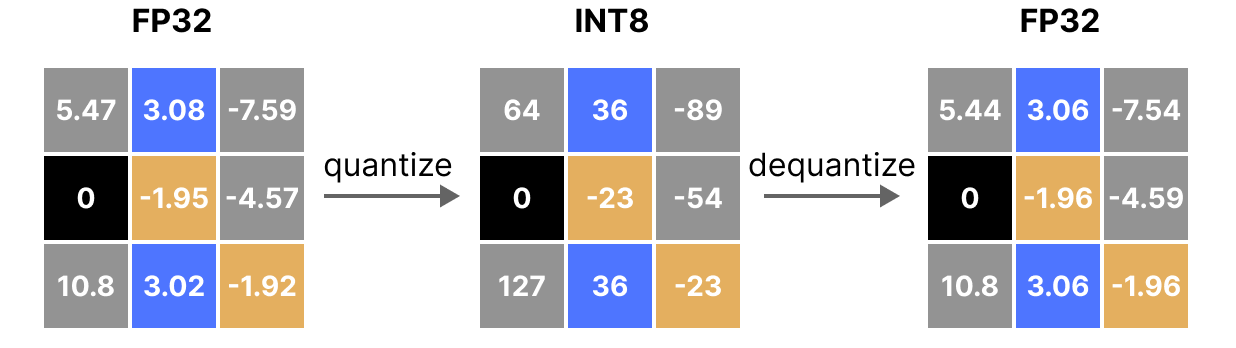
A Visual Guide to LLM Quantization | Devtalk
Overview of LLM Quantization Techniques & Where to Learn Each of Them ...
Practical Guide to LLM Quantization Methods - Cast AI
Faster and More Efficient 4-bit quantized LLM Model Inference | by ...
LLM Quantization Made Easy: Essential Tips for Success
Quantum LLM Inference Transformation | PDF | Quantum Computing | Computing
A Practical Guide to LLM Quantization (int8/int4) | Hivenet
Enable Efficient LLM Inference with SqueezeLLM
GitHub - ccs96307/fast-llm-inference: Accelerating LLM inference with ...
LLM By Examples — Use GGUF Quantization | by MB20261 | Medium
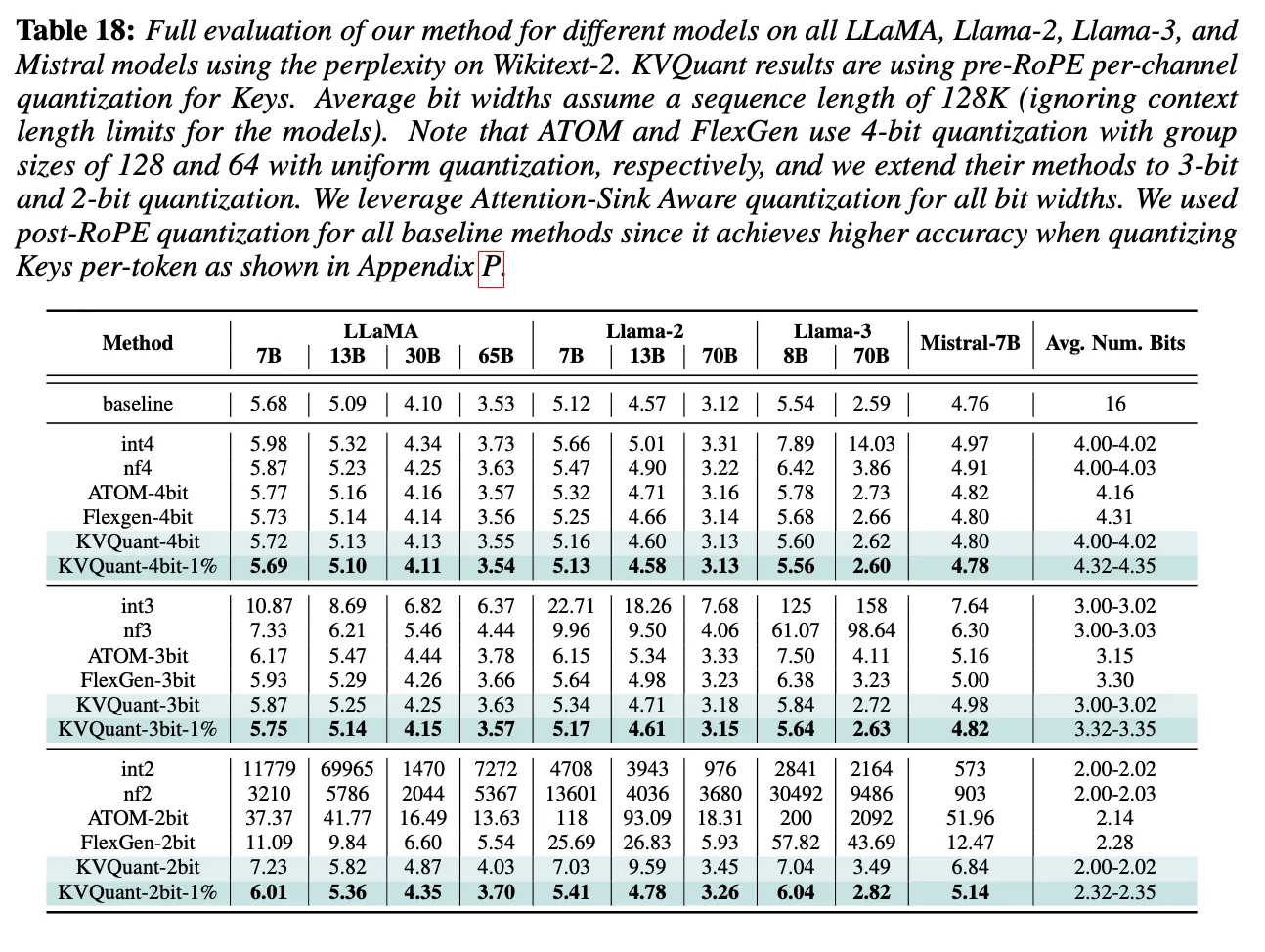
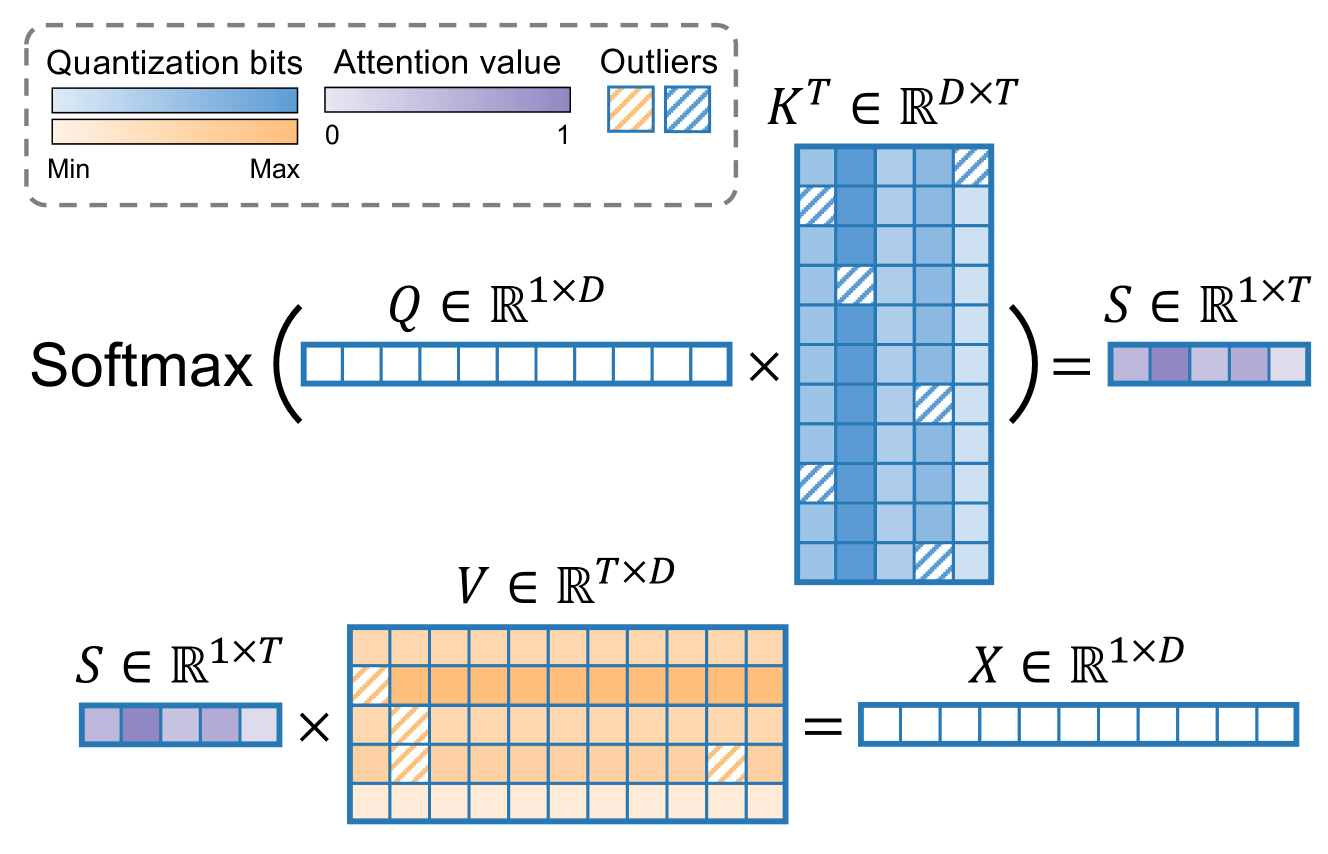
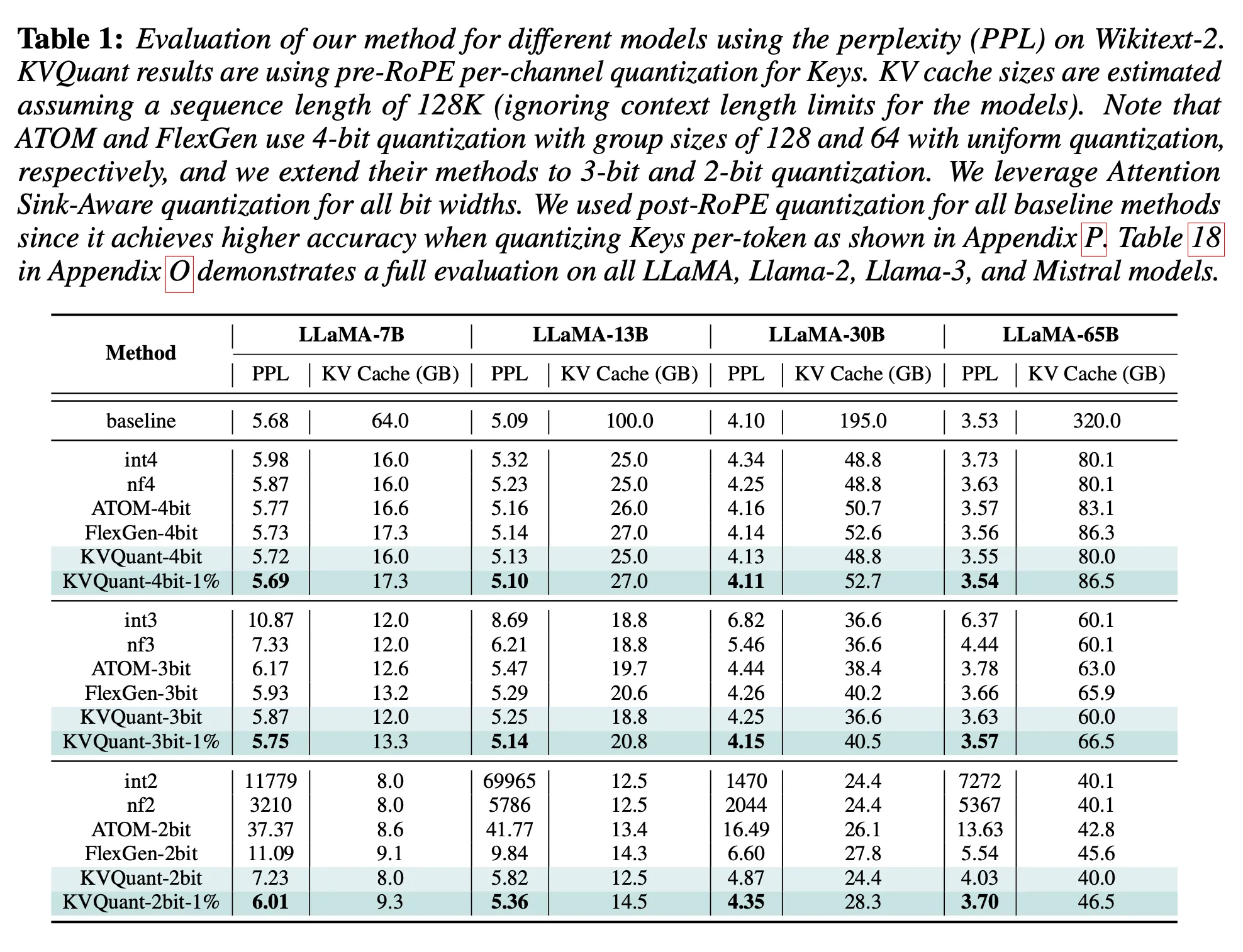
KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache ...
[vLLM — Quantization] AWQ: Activation-aware Weight Quantization for LLM ...
What is LLM Quantization and How to Use Them?
A Beginner's Guide to LLM Quantization
Unleashing the Power of AI on Mobile: LLM Inference for Llama 3.2 ...
LLM Inference Optimization | Speed, Cost & Scalability for AI Models
(PDF) Exploiting LLM Quantization
LLM Quantization-Build and Optimize AI Models Efficiently
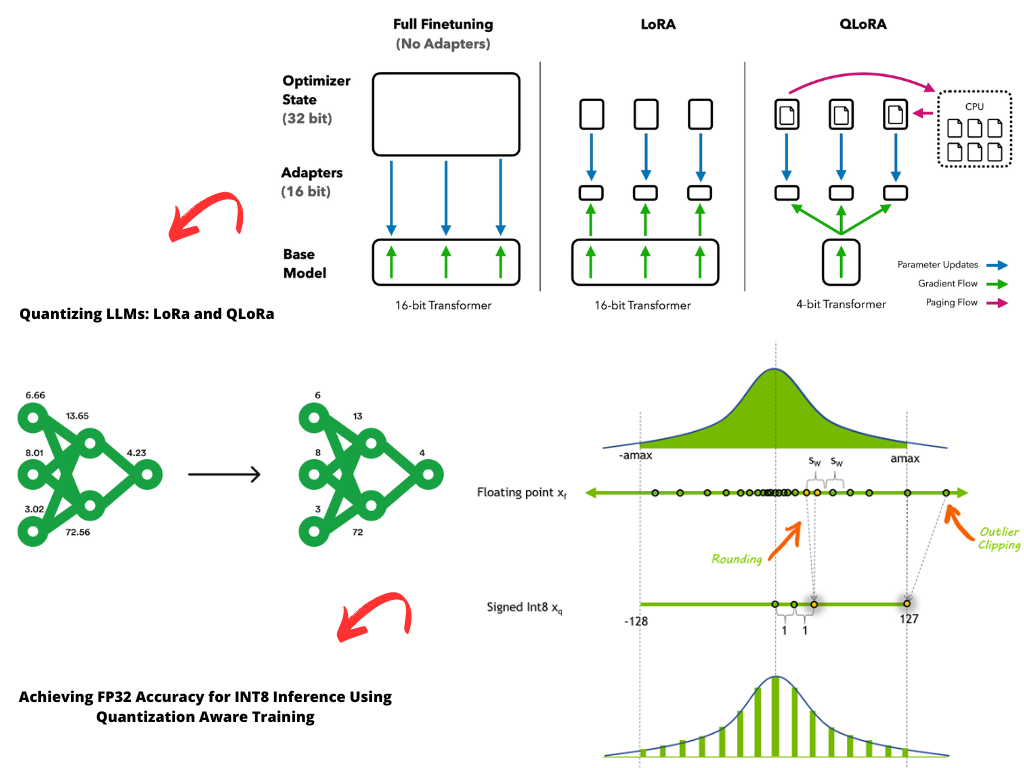
A Visual Guide to Quantization - by Maarten Grootendorst
What is Quantization in LLM? A Complete Guide to Optimizing AI
[论文评述] VQ-LLM: High-performance Code Generation for Vector Quantization ...
Ways to Optimize LLM Inference: Boost Response Time, Amplify Throughput ...
Toward Efficient LLM Inference: A Quantitative Evaluation of ...
LLM Quantization: Making models faster and smaller | MatterAI Blog
What Is LLM Inference? Process, Latency & Examples Explained (2026)
[논문 리뷰] Cocktail: Chunk-Adaptive Mixed-Precision Quantization for Long ...
LLM Training Pipeline Overview | AI Tutorial | Next Electronics
What is LLM Quantization?
Understanding LLM Quantization. With the surge in applications using ...
Optimize Your LLM with Quantization: Save Memory and Boost Performance ...
The AQLM Quantization Algorithm, Explained | by Pierre Lienhart ...
[논문 리뷰] I-LLM: Efficient Integer-Only Inference for Fully-Quantized Low ...
Understanding Quantization: why/how it speeds up LLM inference? | by ...
LLM Compression Techniques to Build Faster and Cheaper LLMs
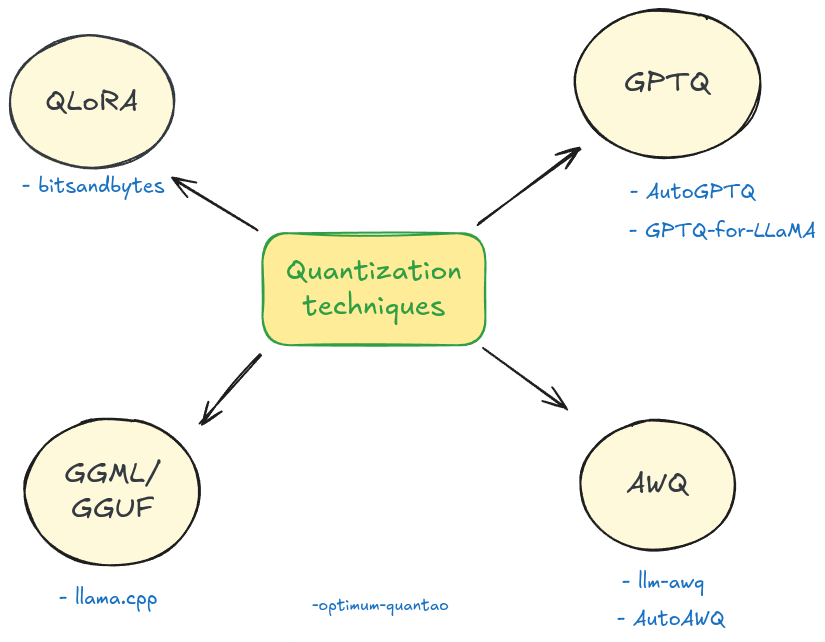
LLM Quantization: Quantize Model with GPTQ, AWQ, and Bitsandbytes ...
What is LLM quantization? - YouTube
What is Quantization in LLM. Large Language Models comes in all… | by ...
I-LLM: Efficient Integer-Only Inference for Fully-Quantized Low-Bit ...
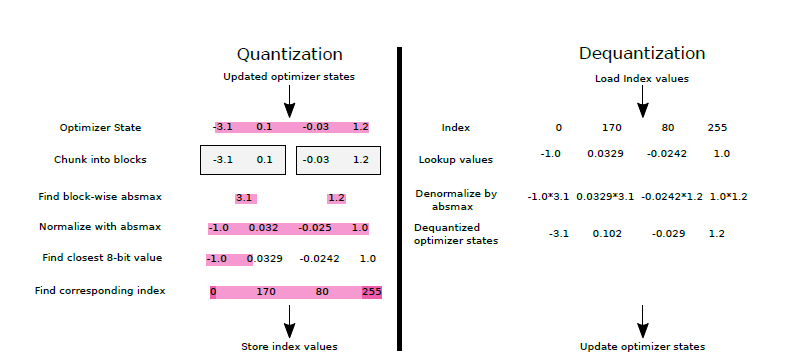
[vLLM — Quantization] bitsandbytes: 8-bit Optimizers, LLM.int8(), QLoRA ...
Maximizing Business Potential with Large Language Models (LLMs)
What are Quantized LLMs?
optimizing-llm-inference-with-quantization/Quantization benchmarks.md ...
LLM-Inference-Acceleration/quantization/onebit--towards-extremely-low ...
模型量化-llm量化 - 知乎
A Survey of Low-bit Large Language Models: Basics, Systems, and ...